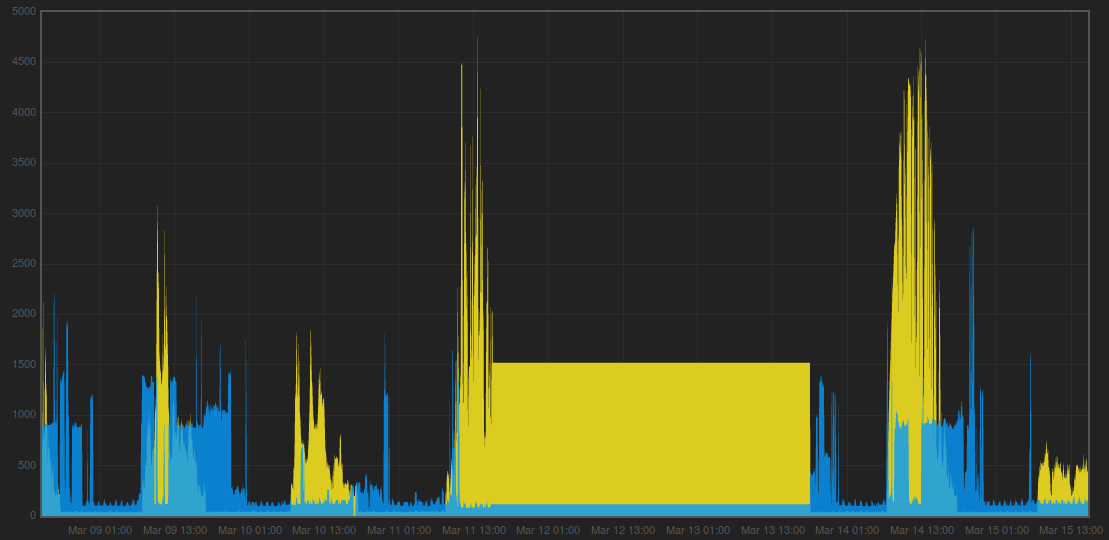
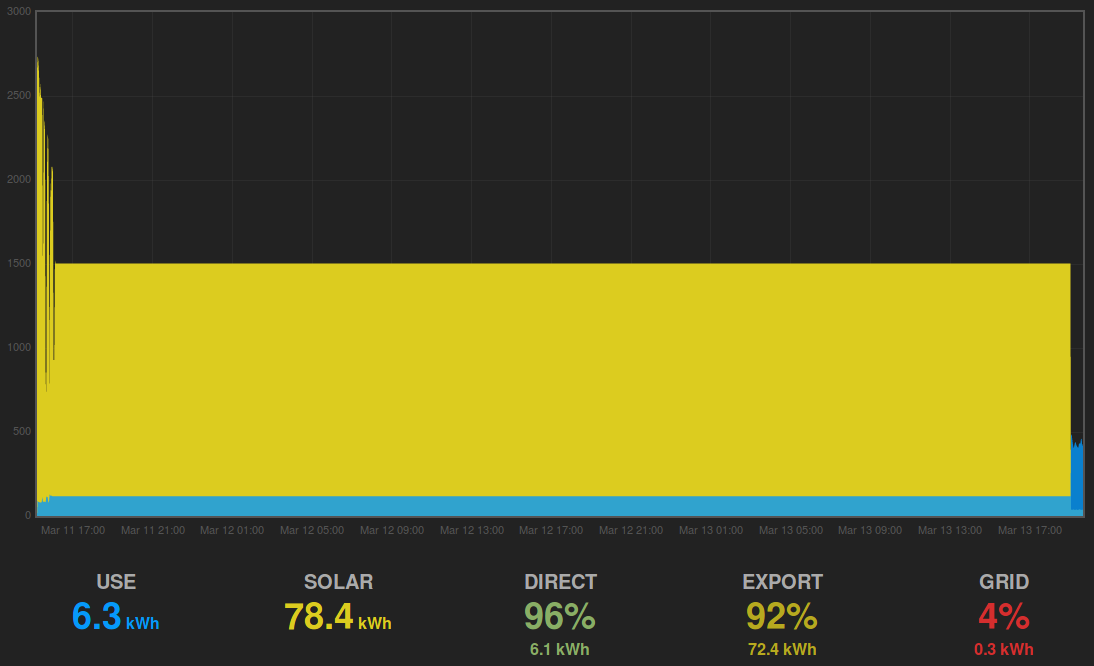
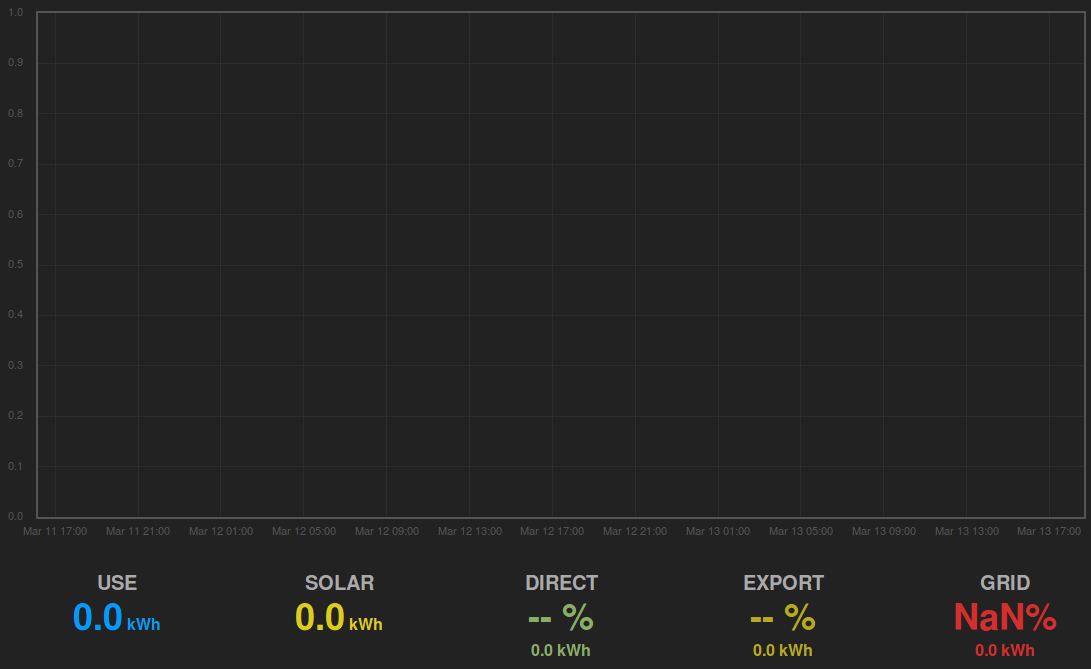
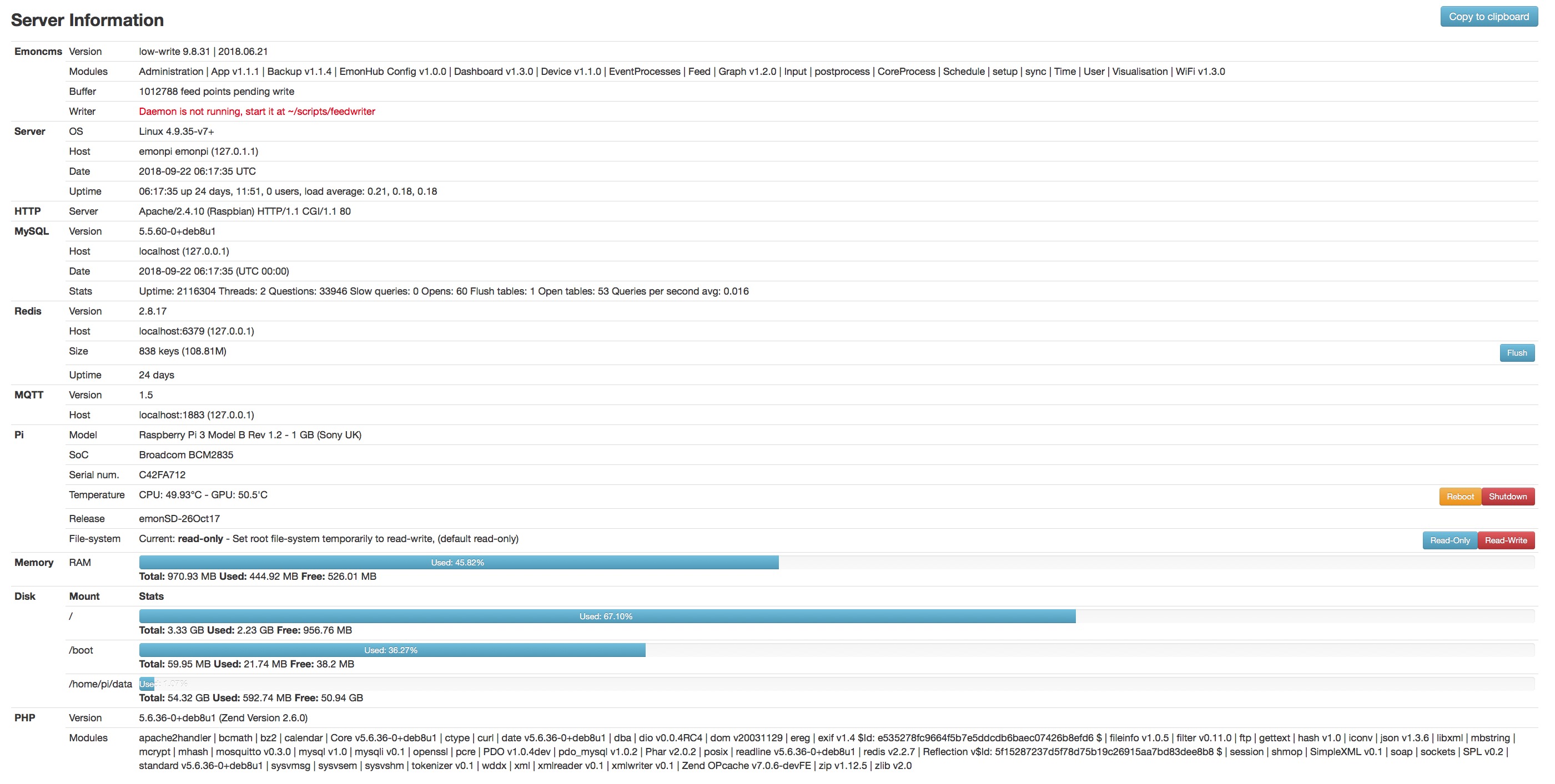
My factory built system goes pretty well but after 20 days or more it stops updating and just a reboot for the web interface restores normal operation.
All the modules are up to date and I even ran the very long process to update to support wifi chn 13
I have saved the logs but to start with this is the clipboard contents when it died and after a reboot.
No rush with a solution as it will be fine for another 20 days plus 
LAST ENTRIES ON THE LOG FILE
#0 /var/www/emoncms/scripts/phpmqtt_input.php(116): Mosquitto\Client->loop()
#1 {main}
2018-04-10 15:17:02.068|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:116
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(116): Mosquitto\Client->loop()
#1 {main}
2018-04-10 15:17:02.069|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:116
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(116): Mosquitto\Client->loop()
#1 {main}
2018-04-10 15:17:02.071|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:116
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(116): Mosquitto\Client->loop()
#1 {main}
2018-04-10 15:17:02.073|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:116
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(116): Mosquitto\Client->loop()
#1 {main}
2018-04-10 15:17:02.075|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:116
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(116): Mosquitto\Client->loop()
#1 {main}
2018-04-10 15:17:02.077|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:116
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.p
It also indicated “Daemon is not running, start it at ~/scripts/feedwriter” in red
After a reboot it says this but seems to always work
LAST ENTRIES ON THE LOG FILE
2018-04-10 20:20:03.666|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:125
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(125): Mosquitto\Client->connect('localhost', 1883, 5)
#1 {main}
2018-04-10 20:20:03.720|WARN|phpmqtt_input.php|Not connected, retrying connection
2018-04-10 20:20:11.283|ERROR|phpmqtt_input.php|exception 'Mosquitto\Exception' in /var/www/emoncms/scripts/phpmqtt_input.php:125
Stack trace:
#0 /var/www/emoncms/scripts/phpmqtt_input.php(125): Mosquitto\Client->connect('localhost', 1883, 5)
#1 {main}
2018-04-10 20:20:11.284|WARN|phpmqtt_input.php|Not connected, retrying connection
2018-04-10 20:20:17.001|WARN|phpmqtt_input.php|Not connected, retrying connection
2018-04-10 20:20:17.002|WARN|phpmqtt_input.php|Connecting to MQTT server: Connection Accepted.: code: 0
2018-04-10 20:20:24.288|WARN|phpmqtt_input.php|Not connected, retrying connection
2018-04-10 20:20:24.307|WARN|phpmqtt_input.php|Connecting to MQTT server: Connection Accepted.: code: 0
Thanks in advance for any ideas.