I noticed something strange this evening just after 22h00. After the sun went down.
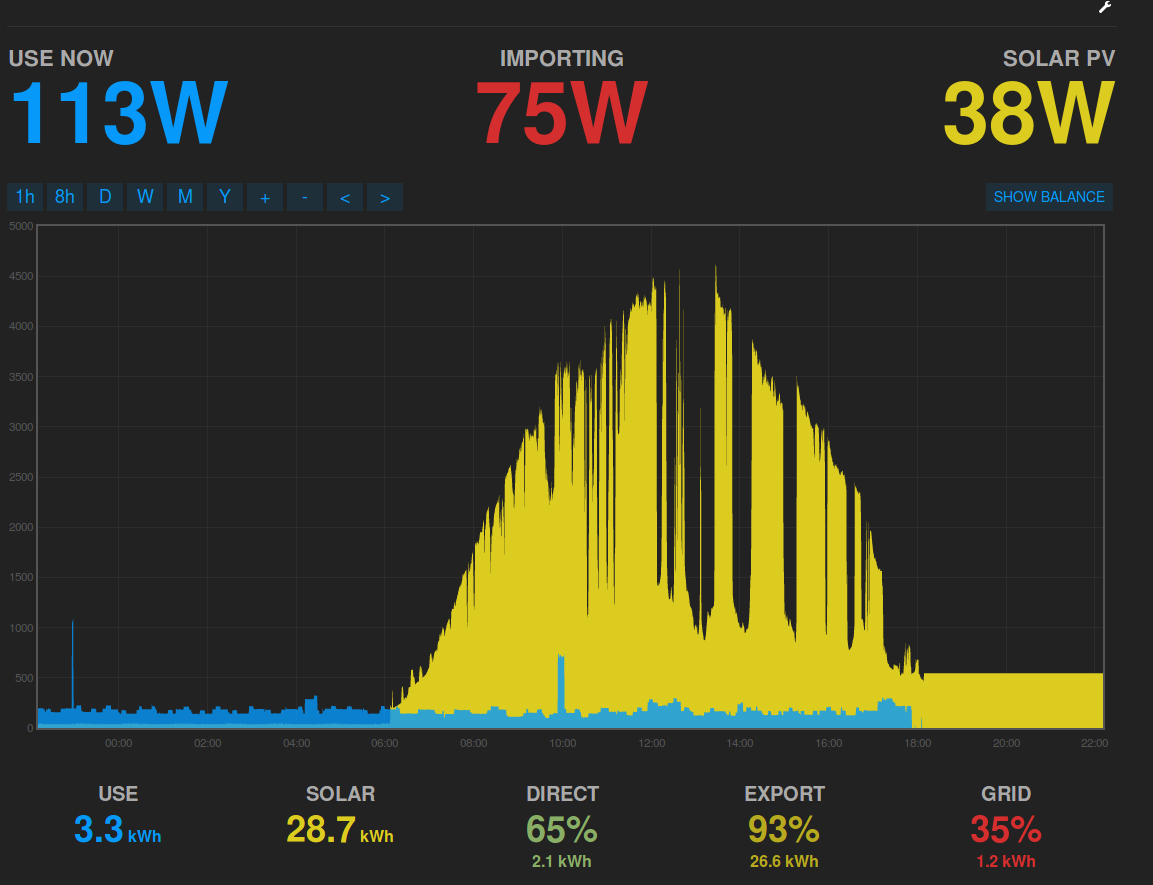
Solar output is 38W, which I believe is reasonably accurate. Ok, it should show 0W but hey, I can correct that number later on. Besides this thread is not about the (in)accuracy of that CT sensor.
As you can see, the graph Solar app graph shows 500W solar output!
The same goes for the usage in blue. 113W while the graph shows 0W.
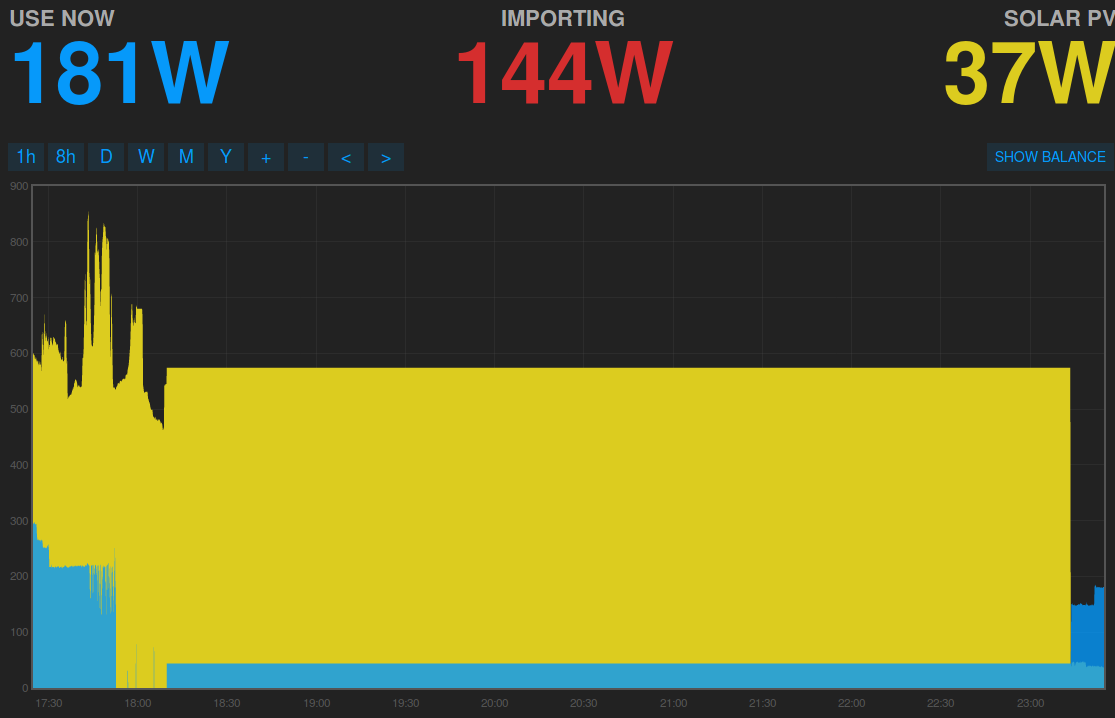
When I looked into the problem a bit further around 23h00. I took another screenshot.

Well, look at that 141W use, which is different from the 113W use and 38W solar.
I switched to the feed list and it showed that all the feeds are updating perfectly fine.

I did a quick and dirty fix since I wanted the measurements to be correct as soon as possible.
pi@emonpi(ro):~$ uptime 21:11:22 up 51 days, 15:52, 1 user, load average: 0.30, 0.14, 0.11 pi@emonpi(ro):~$ sudo reboot Broadcast message from pi@emonpi on pts/0 (Sun 2018-06-03 21:13:00 UTC):
Yes I know, quite blunt. But I only did it after I checked that the watchdog I wrote some time ago (see Reboot Required Every 20 Days Or So To Restore Logging - #13 by pb66 and Collecting Local EmonCMS debug information) detected the anomaly and logged it’s stuff.
After the reboot around 23:13, the graph looks normal again. Well, since around 23:15 that is.
Troubleshoot information available
pi@emonpi(ro):~$ ls -l watchlog/20180603-162201+0000/ total 596 -rw-r--r-- 1 pi pi 18021 Jun 3 16:22 cmd-ps.txt -rw-r--r-- 1 pi pi 0 Jun 3 16:22 cmd-service.txt -rw-r--r-- 1 pi pi 14380 Jun 3 16:22 cmd-top.txt -rw-r--r-- 1 pi pi 109 Jun 3 16:22 data.txt -rw-rw-rw- 1 pi pi 7915 Jun 3 16:20 emoncms.log -rw-r----- 1 pi adm 559827 Jun 3 16:22 syslog
Apparently the service --status-all did not log.
Top at that time shows a load of 66!!!
pi@emonpi(ro):~$ head -n10 watchlog/20180603-162201+0000/cmd-top.txt top - 16:22:02 up 51 days, 11:02, 0 users, load average: 66.42, 49.84, 27.56 Tasks: 181 total, 3 running, 178 sleeping, 0 stopped, 0 zombie %Cpu(s): 2.5 us, 0.9 sy, 0.0 ni, 96.4 id, 0.2 wa, 0.0 hi, 0.1 si, 0.0 st KiB Mem: 994232 total, 416828 used, 577404 free, 9624 buffers KiB Swap: 0 total, 0 used, 0 free. 142272 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 143 root 20 0 10232 3052 2788 S 13.9 0.3 27:26.86 systemd-jo+ 1961 www-data 20 0 115500 13444 8240 S 13.9 1.4 32:11.86 apache2 7305 pi 20 0 6804 2384 2084 R 13.9 0.2 0:00.07 top
Will look into this further at a later time. Pointers welcome.