For some time now we have used ext2 with a block size of 1024 for the emonSD data partition. Following research I did, documented here: Learn | OpenEnergyMonitor. The lower block size of 1024 resulted in ~half the disk write load compared to 4096. My tests for ext2 vs ext4 seemed inconclusive.
Does anyone with a more in depth understanding on ext2&4 filesystems have a view on this?
The /proc/diskstats file displays the I/O statistics
of block devices. Each line contains the following 14
fields:
1 - major number
2 - minor mumber
3 - device name
4 - reads completed successfully
5 - reads merged
6 - sectors read
7 - time spent reading (ms)
8 - writes completed
9 - writes merged
10 - sectors written
11 - time spent writing (ms)
12 - I/Os currently in progress
13 - time spent doing I/Os (ms)
14 - weighted time spent doing I/Os (ms)
Command to return ‘sectors written’ for given partition:
Thanks @Greebo, I haven’t looked at F2FS looks interesting and worth investigating.
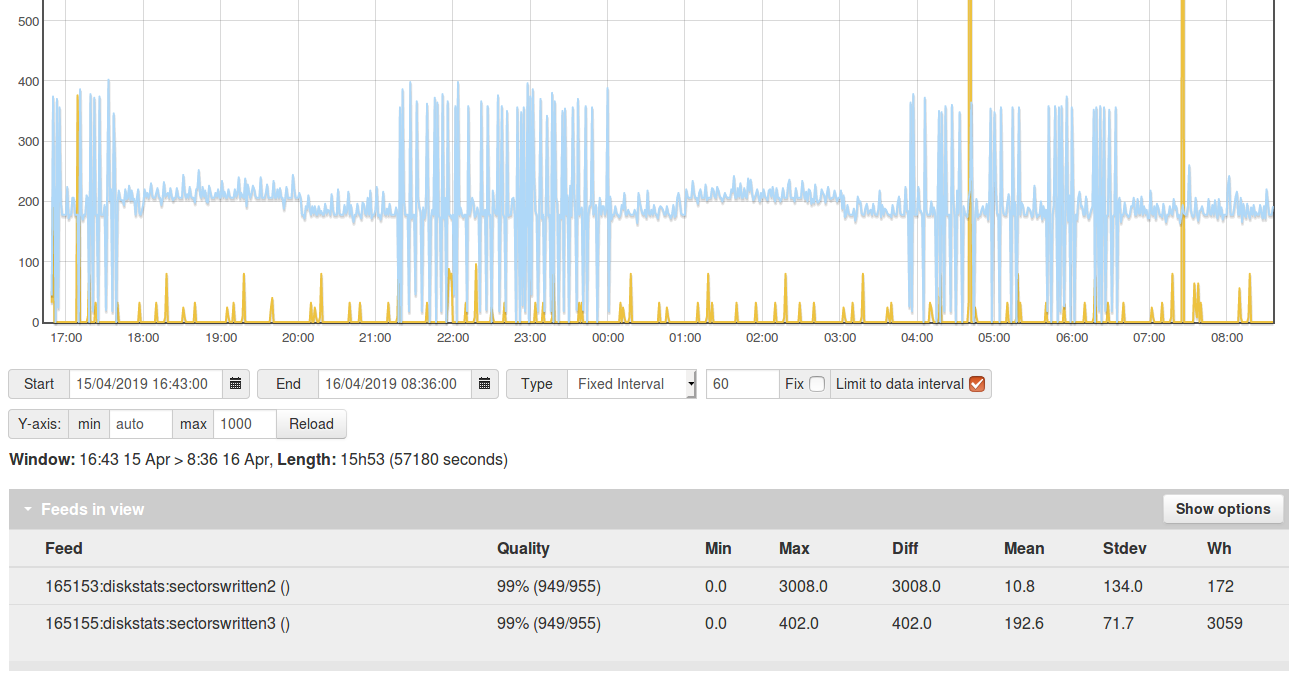
I’ve been logging sector writes overnight, here are the results for the emonSD-30Oct18 image. Blue series is the data partition (ext2 filesystem blocksize: 1024), Yellow series is the OS partition (ext4 blocksize 4096)
The same test running on the pi with installation based on the build script on a stock raspbian stretch with everything on an ext4 partition with block size 4096 and only 23 feeds, Im getting 800 sectors per minute 6.7 kb/s (4x the ext2 block size 1024 system), Is it really that simple? block size is 4x that of the ext2 partition, even though number of feeds being written is less than half…
Edit: on the 2nd test here there are large spikes every hour. If you remove these spikes the write rate is ~450 sectors/minute or 3.75 kb/s, 3.75 kb/s / 1.6 kb/s = 2.34x larger write rate for 40% of the number of feeds.
Im not 100% sure, it was a while back now when I did the more detailed research into the PHPFina feed engine design. It either had to do with not being able to read new data from the file when it was still open? or it was a result of the file potentially being written as part of a single apache2 instance resulting from a http post request. For most systems this case is not relevant any more as feed are written to by the feedwriter as part of a always running background process and so in theory files could be kept open.
I was surprised at yr result and intrigued by Bill Thomson’s suggestion in a related thread re: sudo cat /proc/diskstats and so decided to try it …
diskstats does not provide very user friendly output - no averages - just totals since the last boot up …
The /proc/diskstats file displays the I/O statistics
of block devices. Each line contains the following 14
fields:
1 - major number
2 - minor mumber
3 - device name
4 - reads completed successfully
5 - reads merged
6 - sectors read
7 - time spent reading (ms)
8 - writes completed
9 - writes merged
10 - sectors written
11 - time spent writing (ms)
12 - I/Os currently in progress
13 - time spent doing I/Os (ms)
14 - weighted time spent doing I/Os (ms)
In my application, there are 5 instances of emonTx/RPi3 running the emonSD image Oct 2018 updated to 9.9.8 to monitor a large PV installation (3 phase) and I ran diskstats on …
Node 11 at the Inverter
Node 13 at the Grid Supply Meter
watchman - an ‘emoncms server’ (without an emonTx) on the local network just receiving data from the other nodes
… and got the following results …
Focussing just on sectors read & write and adjusting to per min values, in summary the results were …
Instance
No. of Sensors
No. of ‘active’ inputs via HTTP
No. of Data Feed files created
Partition
Sectors Read per min
Sectors Written per min
Sectors Total per min
Percent
Node 11
1
0
6
OS
111.5
6.4
117.8
81%
Data
6.6
21.8
28.4
19%
Node 13
4
0
23
OS
82.7
42.9
125.6
54%
Data
29.4
78.0
107.3
46%
watchman
0
9
13
OS
59.4
7.9
67.3
34%
Data
8.2
122.4
130.6
66%
My conclusions are …
Re the OS partition - Unsurprisingly sectors written to are vey much less proportionately than sectors read tho’ this is very dependent on the number of sensors./feed files created.
Re the Data partition - Unsurprisingly, sector writing is more prevalent than sector reading. And also unsurprisingly, this is very marked in the case of watchman which effectively just runs emoncms.
In retrospect, it’s beneficial that watchman runs the OS & Data partitions on a USB HDD. Tho’ that is based on my understanding that writing to an SDHC is more potentially ‘life shortening’ than reading from an SDHC ?
Thankyou for sharing your results @johnbanks , it will be good to compare and monitor this across many systems, to verify that we are getting consistent results.
Another useful tool for working out what is writing to disk is iotop:
sudo iotop -oa
-o only shows processes writing to disk
-a shows cumulative totals
I’ve been able to reduce the OS write load significantly by:
changing log2ram to RSYNC and then daily rather than hourly sync, I would like to look into this in more detail, I haven’t applied your modifications yet @pb66. By setting the sync to daily I have effectively turned this source of writes off in my tests. log2ram seems to be responsible for the large spikes seen in post 5 above.
Placing both /tmp and /var/tmp in a tmpfs as per emonSD-30Oct18 fstab configuration - this removed the baseline write load seen on the OS partition, 112 sectors/minute, 0.9 kb/s
Im now down to (on the build script based system):
data partition (/var/opt/emon) 16.4 sectors/minute = 0.14 kb/s
OS partition 6.4 sectors/minute = 0.05 kb/s
I’d suggest that these optimisations (including the log2ram) are made optional within the install process so they can not be implemented by users not on flash memory.
With emonhub on log level warning & demandshaper turned off, the logs fill up much more slowly. Im going to provide better debug/warning level logging for both feedwriter and demandshaper to improve it further. I think I would personally like to have ‘warning’ as the default log level across the emon scripts with the option to set to ‘debug’ if there is an issue and ‘warning’ level is not enough.
I agree that making this all user configurable is a good idea.
Its a good question. If higher write rate is equal to lower SD card life span then making efforts to reduce write rate makes sense. How significant the difference is I dont know. The optimisations so far have reduced the OS partition write rate by 97%. It is of course a balance between functionality and reducing write rate. I think an hourly log2ram sync using RSYNC and the tmpfs changes for /tmp and /var/tmp may do most of the reduction, I will keep testing.
I do think there needs to be a more dynamic solution to the problem (and we risk moving off the thread title - perhaps another split) of the logs filling up.
I’d advocate something like the use of monit and the space usage test to trigger a log rotation if /var/log fills up.
Just a point, as I have run into this issue, mounting the data partition differently to the OS makes expanding the SD Card really hard! Expanding Filesystem.
What is the rationale for mounting the data partition separately? Are there really any significant gains to be had in a world of such large SDCards for pennies?
The data partition is ext2 and uses a different block size, this is part of the low-write optimisations.
I do not think it is the financial cost of the sd card that is being considered here. It’s the loss of data and aggravation of rebuilding a new sdcard image each time it fails.
For the record, whilst i see the reduction in write levels reported and welcome any reduction in write levels. I was never totally sold on the idea of a 3rd partition on the same drive. I would prefer to see a small usb stick in place of the 3rd partition if it must be separated, that would lower the writes on the sdcard significantly further. I do however like with having a root /data folder for c ollating all my data and mysql etc for easy backup and or easier retrieval in the event of a fail.
Yes I get that, but does block size change the number of writes or just reduce the space used by small amounts of data? If the latter, when a 4Gb card was the largest you could get and was very expensive, I understand the optimization. Does this rationale still hold?
It is not just about the cost of the card, it is about the cost of the storage which has dramatically reduced since this design was implemented. But that is not mitigated by the smaller block size is it?
Loss of data is down to a poor backup regime - all storage devices are prone (at some point) to failing, even a USB stick.
Yes agreed but I presume you mean a logical folder rather than a physical partition? If all the data is grouped under any logical location it makes things far simpler (which is what DietPi does by default ).