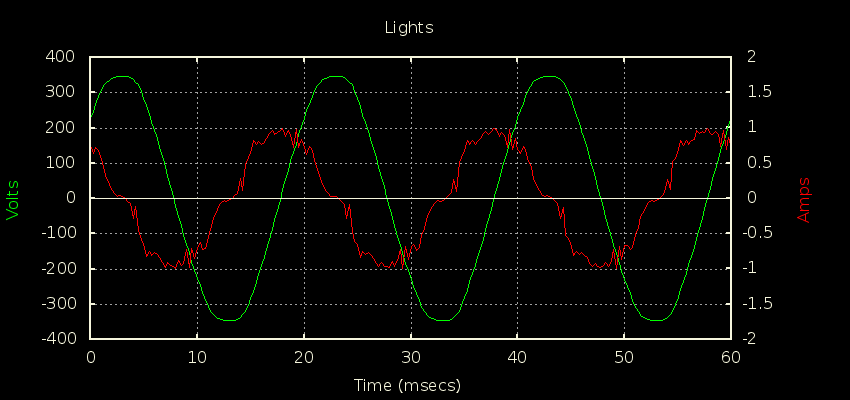
The standby current on this thing is a shocker: 0.66A just sitting there waiting for someone to press a button. 3W Real and -165 VAR Reactive, PF of 0.018.
The standby current on this thing is a shocker: 0.66A just sitting there waiting for someone to press a button. 3W Real and -165 VAR Reactive, PF of 0.018.