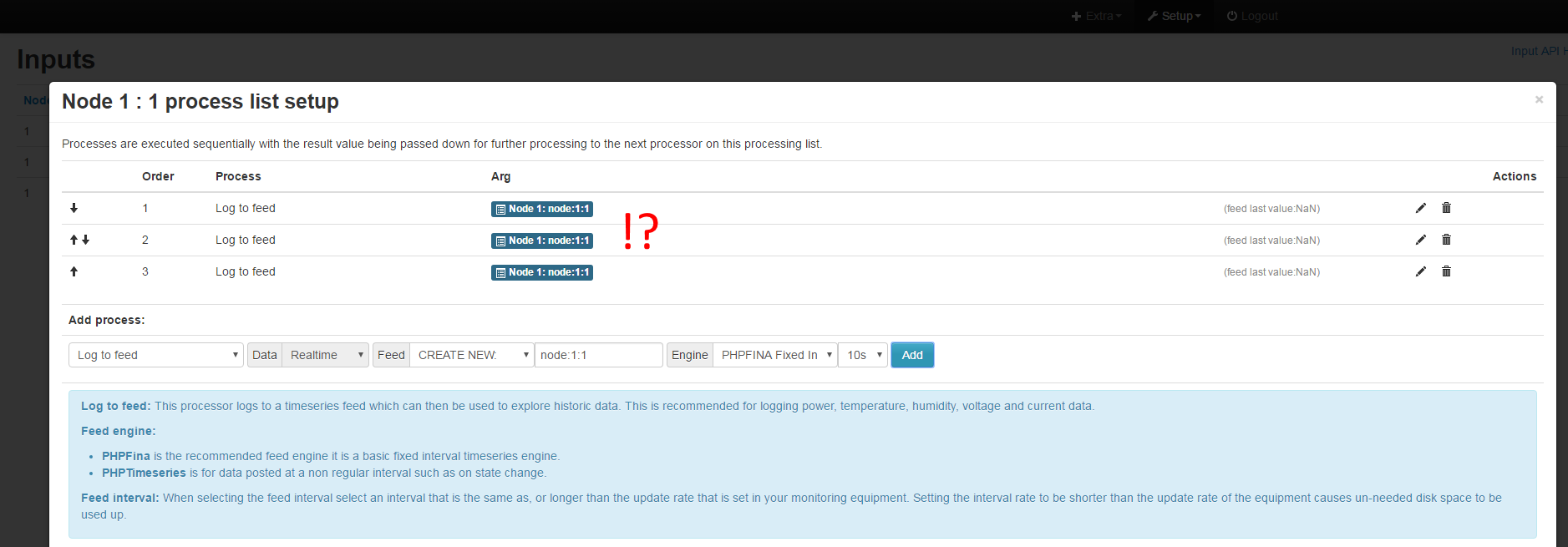
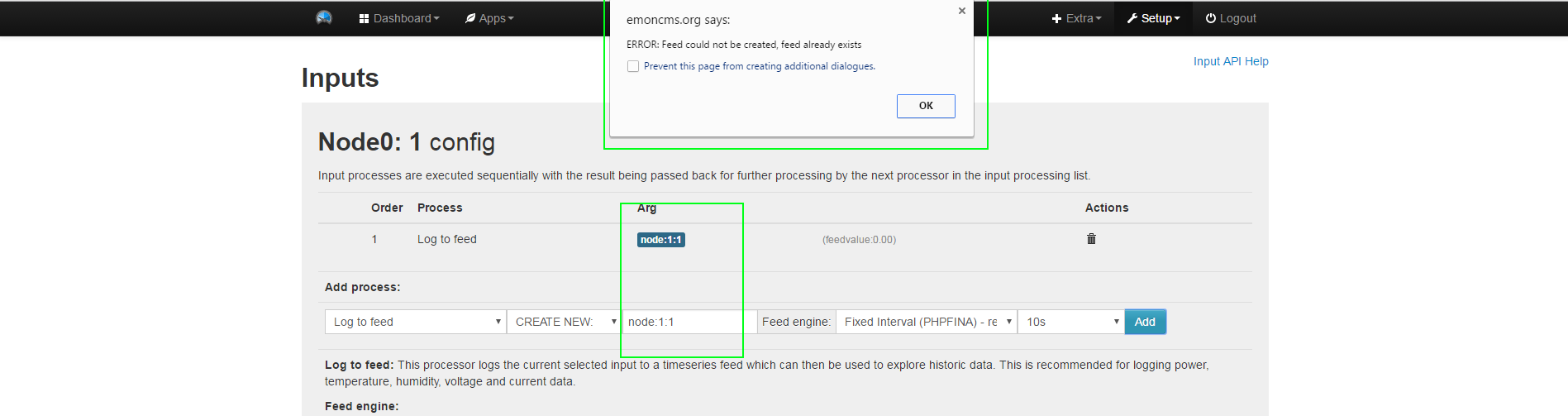
I checked out the latest version of the EmonCMS, and noticed some odd behaviour when using the “process list” functionality from the Inputs view page.
In this latest version, the process module allows you to add feeds without properly checking if the feed already exists. The production emoncms.org site has a different or older version of the process module that handles this type of exception properly.
Is this intended functionality? Or was this a work in progress?
Example of current master branch making multiple feeds:
On another note:
In the feeds table, there is the fields name and tag. What is the difference? Where would this be used?
Same in the inputs view page, there is key and name value? Whats the difference between the two? When are they used?
Well I’ll start with the easy one! - name & tags
If you have a mixture of feeds, for example weather data, power, water etc, you can add the same tag to each of the respective feeds, such as the tag ‘Weather’ and all feeds relating to weather will be grouped together in the same category. You can then expand or contract all weather feeds in just one click.
Version 9 changed the way in which feeds are identified.
Pre v9, the feed was identified by it’s name which must be unique, however in v9, the feed number is the identifying factor and therefore you can have 2 feeds with exactly the same name.
Anybody else have answers to the remaining questions?
Inputs view page, there is key and name value? Whats the difference between the two? When are they used?
What is this realtime, histogram and daily data type used for? When is it applicable?
From each node, you could have several inputs such as power, battery voltage, RSSI, etc. The key is what is assigned to discriminate between them, like a heading and sub-heading. The name however is user assigned, and can help you identify individual inputs.
The “key” is actually the name field of the db schema, when data arrives without a name it is automatically given a numerical name much like an array index. the numerical name or index is a very useful way of referencing the inputs as the bulk upload allows you to use an array eg [[1464303710,10,123,456,789][1464303710,11,123,456,789] ] is a very efficient way of posting multiple sets of input values, the first would post 123 to “node” 10 “key” 1, 456 to “node” 10 “key” 2 etc.
The key can be changed by the user to a text name so that you can use json and terms like “power1:123” to post data, but then you lose the ability to use bulk upload to post to that named input as it is no longer an array index.
The “name” is actually the description field in the db schema, this is usually used to hold the name of the input eg power1 etc so that use of the numerical “keys” can be retained, it currently serves no purpose other than holding a full name/description to explain the “key” and is pretty much redundant if named inputs are used instead of index numbers.
There has always been a battle between the use of a numerical index to facilitate bulk upload and the use of names in human readable json, both within the same field, in an ideal world we would simply change the json api to also use the description field for the name and have the best of both worlds but for some reason this suggestion never gains any interest.
The way the “nodes” and “keys” are used is pretty much the same as the feeds and group tags, the individual “keys” AKA inputs are grouped by “node” tags.