I recently acquired from a friend an EmonTx and EmonPi. I’ve set it up with a couple of current transformers but I decided I wanted power factor & frequency info too. I’ve added that on EmonTx and put a modified config in emonhub.conf. However that made the firmware on EmonTx dangerously close to size limits so I looked for savings. I was interested in how the continuous monitoring worked so I’ve looked at that code. Turning the multiple floating-point divides in EmonLibCM_get_readings() to one inversion and multiplies saved over 500 bytes, but looking at the ADC interrupt routine, it’s very large and I worried that it wouldn’t complete in 104 us. I’ve hacked on that to put the accumulator variables in structs - one for voltage and an array of structs for currents so I can use memcpy and memset. Also rather than doing the whole copy at the end of the 10 sec accumulator period in the voltage ISR call, it’s now split so that, when the data is ready for copying, each ISR invocation copies only its own data, with the ‘ready’ flag set after the last current ISR call. The efficiencies in doing that saved 2880 bytes in total. If you want to do a new version of EmonLibCM based on this, PM me and I’ll send a copy.
Welcome John, to the OEM forum.
It’s unlikely the present version of emonLibCM will be seriously revised, because the Atmel 328P is essentially unavailable at present.
You’re wrong about
it does complete in well under the 104 µs - less than half the processor’s time is spent in the ISR. Here’s the evidence:
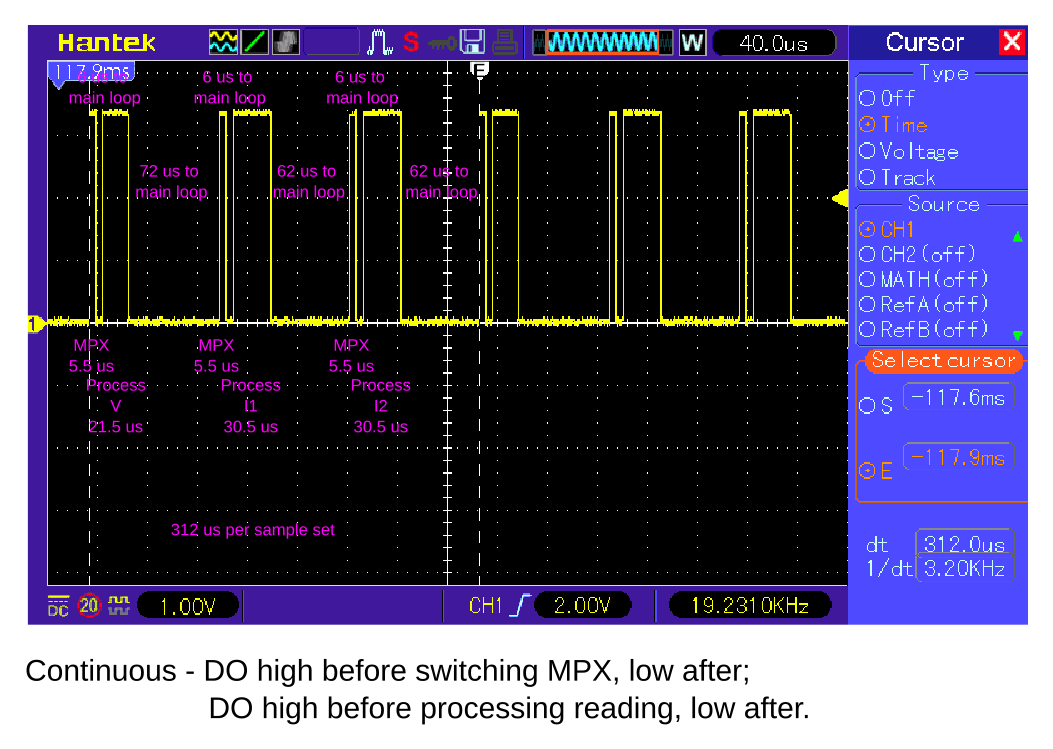
Did you really think this hadn’t been checked?
Well, that pic shows the ISR during most cycles. However when you get to the end of the 10 sec period and want to copy all the accumulator variables (line 897 in emonLibCM.cpp) then that takes a lot of time. For, say, 4 current channels plus the voltage channel the accumulator variables amount to 128 bytes. To copy them using the inlined memcpy() takes 896 cycles and the memset() to zero them takes 640 cycles. That’s 1536 cycles out of 1664 cycles available to the ISR before the next ADC interrupt (104 us with 16MHz clock). That’s the best case. The actual code with a for loop takes far longer because the code is much less efficient.