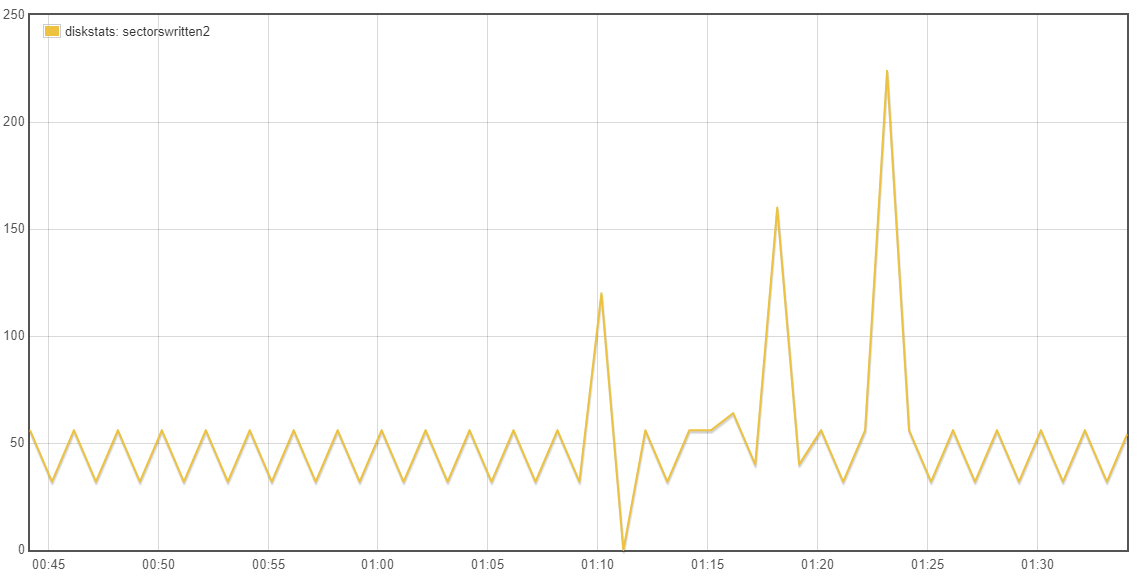
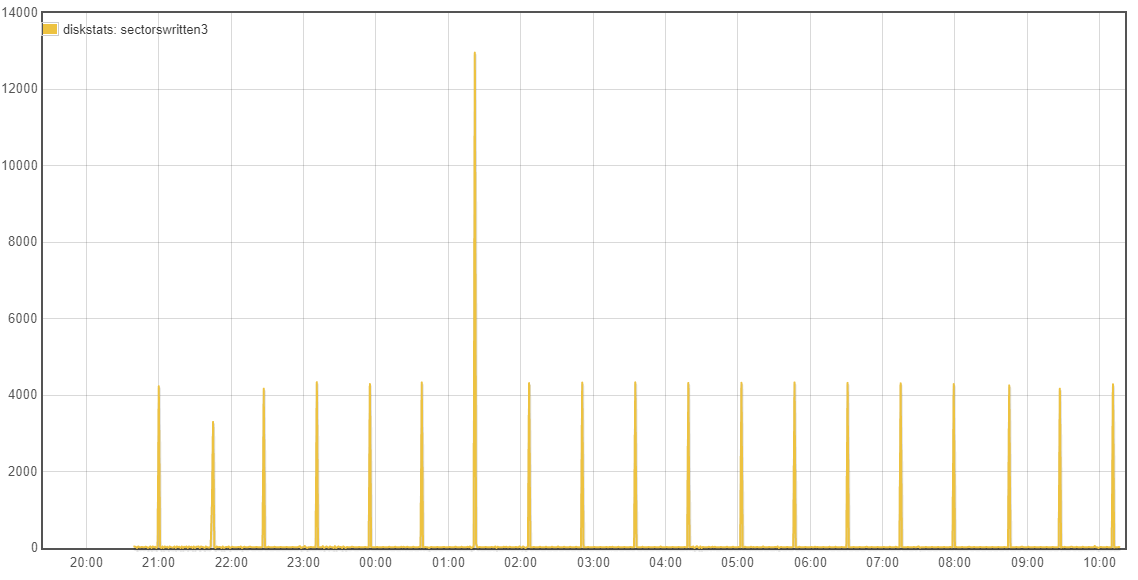
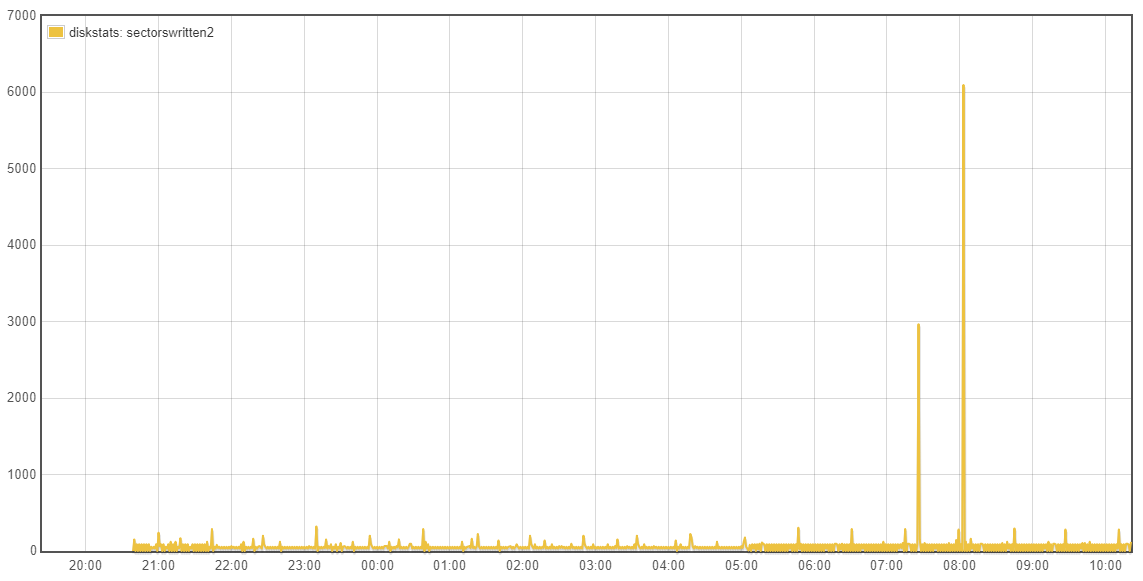
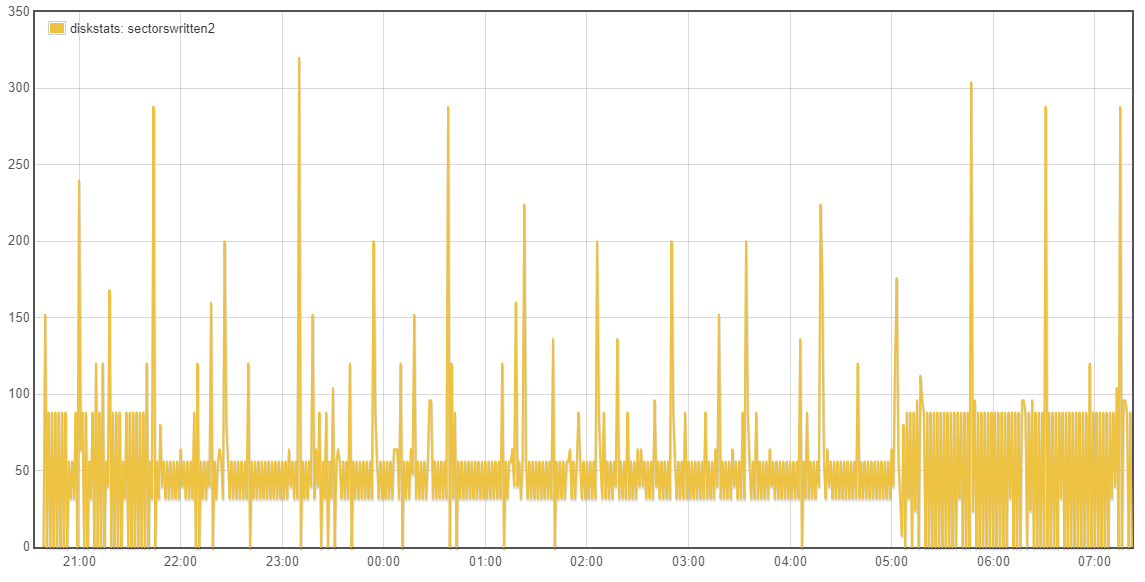
Yes that is it general intention of rsync but it is not that clear cut.
From the wiki page you linked says “The rsync algorithm is a type of delta encoding, and is used for minimizing network usage.” and it seems that network saving could be at a cost of additional disk writes if not set up correctly.
For example, from the rsync man page
-W, --whole-file
With this option rsync’s delta-transfer algorithm is not used and the whole file is sent as-is instead. The transfer may be faster if this option is used when the bandwidth between the source and destination machines is higher than the bandwidth to disk (especially when the lqdiskrq is actually a networked filesystem). This is the default when both the source and destination are specified as local paths."
We are doing local to local rsync’s! So the default operation is to copy the whole file, this is because it is considered faster to “just copy all” on a local to local device where network resource is unimportant.
There was a issue raised on L2R repo about the use of --whole-file (Why only copy file when using rsync? · Issue #25 · azlux/log2ram · GitHub) as it is specifically defined in L2R’s rsync command. The use of --no-whole-file would fall back to only transferring the delta (changes). I choose the word “transferring” rather than “copying” for a good reason.
When rsync does it’s thing it can be working on live files being accessed by other services, therefore at the destination it creates a copy of the target file, makes the changes to that and then deletes the original target and renames the new updated file to replace the original. This results in the whole file being re-written regardless of the --no-whole-file setting. So nothing is gained (in disk writes) by setting just that unless the --inplace option is also used.
–inplace
This option changes how rsync transfers a file when the file’s data needs to be updated: instead of the default method of creating a new copy of the file and moving it into place when it is complete, rsync instead writes the updated data directly to the destination file.
This has several effects: (1) in-use binaries cannot be updated (either the
OS will prevent this from happening, or binaries that attempt to swap-in their data will misbehave or crash), (2) the file’s data will be in an inconsistent state during the transfer, (3) a file’s data may be left in an inconsistent state after the transfer if the transfer is interrupted or if an update fails, (4) a file that does not have write permissions can not be updated, and (5) the efficiency of rsync’s delta-transfer algorithm may be reduced if some data in the destination file is overwritten before it can be copied to a position later in the file (one exception to this is if you combine this option with –backup , since rsync is smart enough to use the backup file as the basis file for the transfer).
WARNING: you should not use this option to update files that are being
accessed by others, so be careful when choosing to use this for a copy.
This option is useful for transfer of large files with block-based changes
or appended data, and also on systems that are disk bound, not network bound.
There is an L2R issue discussing use of --in-place (Current rsync usage may cause excessive SD card writes · Issue #45 · azlux/log2ram · GitHub) and quite rightly at that time there were concerns about the rotated log files. My modifications to L2R negate these issues and concerns as the rotated files are not handled by L2R directly. L2R only sets the logrotation “olddir” directive so that when logrotate occurs, it uses olddir and puts the files to another directory.
With these changes the rsync option should only append the changes directly to the existing file.
Although I have not fully tested this, I believe the rsync command in L2R should be changed from
to
rsync -aXv --inplace --no-whole-file --delete --links $RAM_LOG/ $HDD_LOG/ 2>&1 | $LOG_OUTPUT
I have removed the -W option and added --inplace --no-whole-file, I will update my repo now by adding a new feature branch called “rsync_mods” but unless you plan to reinstall, it is easier to edit in place with sudo nano /usr/local/bin/log2ram, I just commented out the original line and added the new line below it so it is easy to revert.
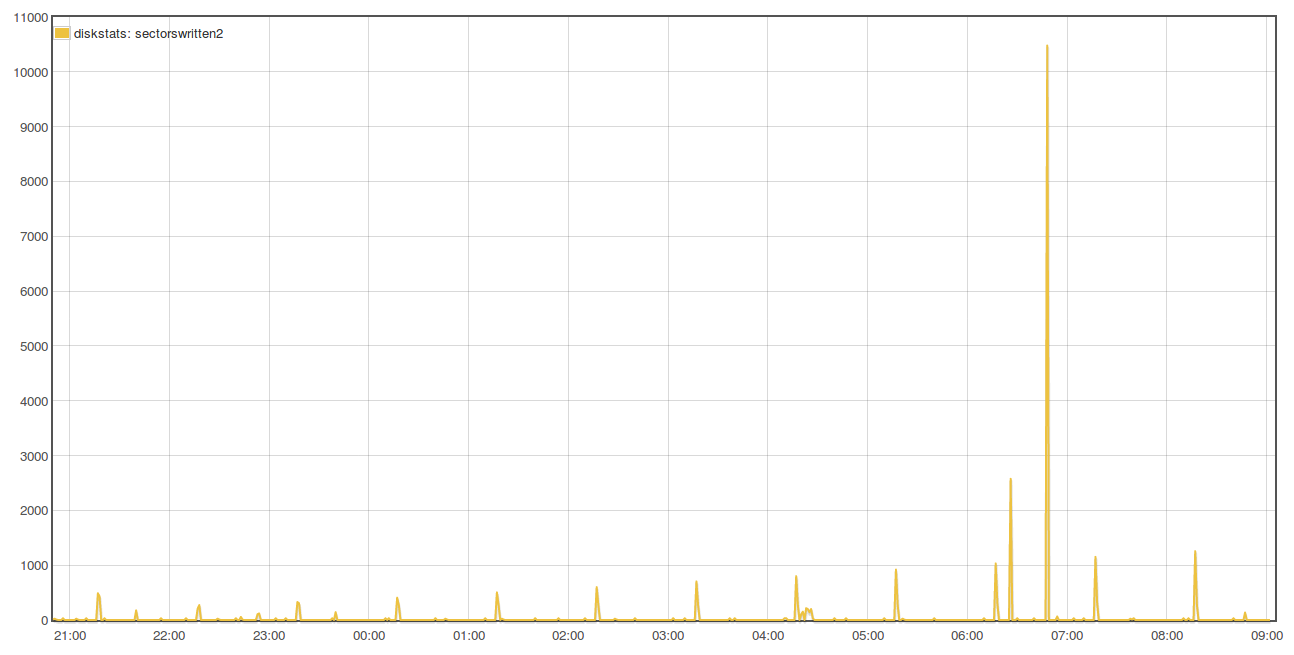
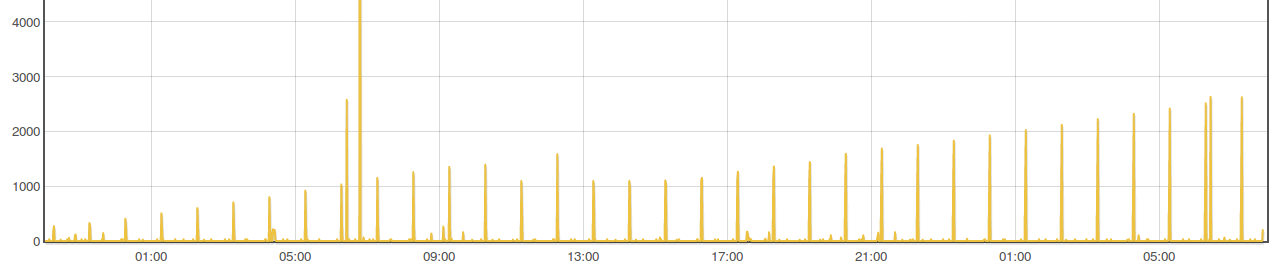
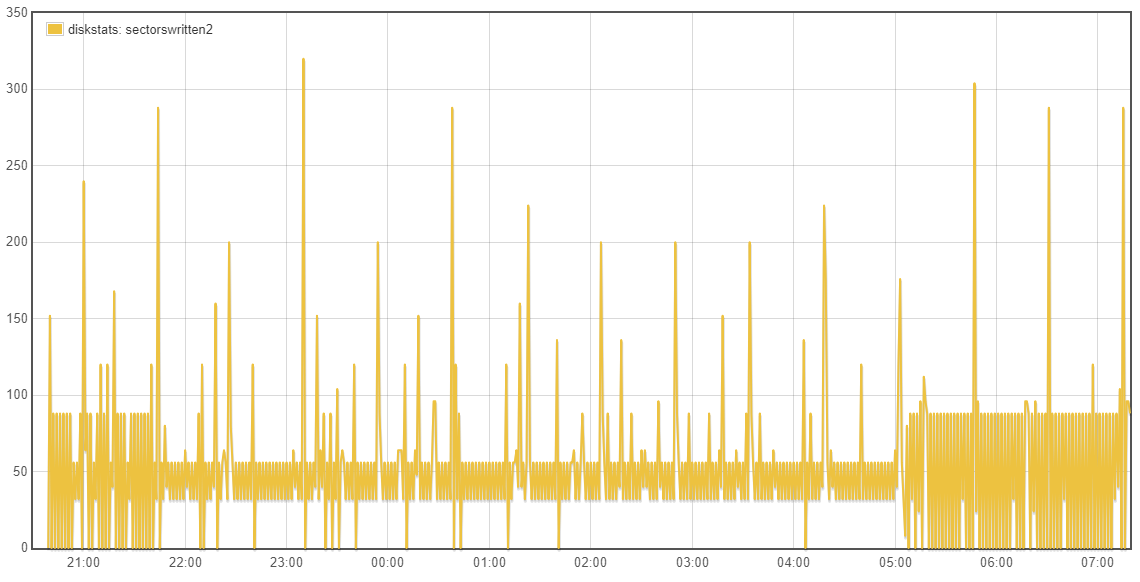
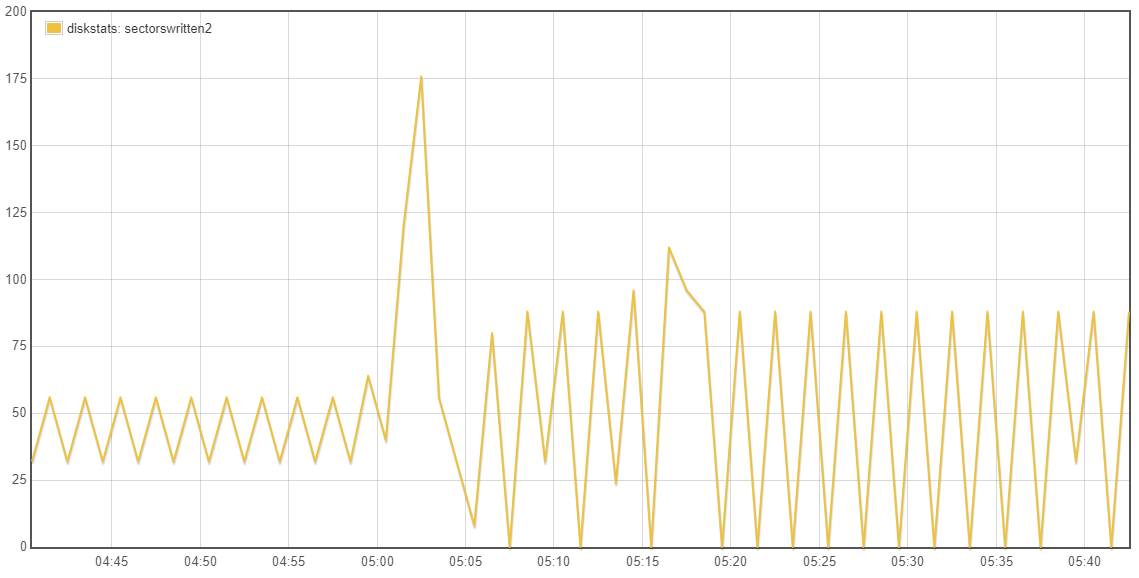
Going back to whether the tests being done are valid/relative, the emonSD image creates a lot of log messages, had these been previously retained and better managed they would have been very useful to debug all the issues we’ve seen over the last few years. I’m keen to retain a higher level of logging until we are confident all the services are as error free as possible. It was because I expect a high turnover of logs that I had preferred to stick with the cp option in L2R and avoid investigating the potential advances with L2R rsync at this time. When there is a high log rate the files will be rotated more frequently and regardless of the L2R mode, we will be pretty much copying a whole new file each time even with the rsync mode operating as expected.
I believe moving to L2R (in basic cp mode) fixes the retention and folder structure for reboot issues and with the new longer retained verbose logs we can improve both the emonSD software and also L2R so one day we can indeed reduce the loglevels of the services once they are all fairly error free and also switch to a more streamline L2R through thorough testing over time.
With your current testing strategy of reducing the log levels you are introducing a unrealistic test which is causing a major reduction in the efficiency of L2R as the log files are only getting small additions to them, therefore the same whole file is being copied over and over each hour rather than the hourly rotated high traffic logfile being sync’d where the whole file is new and therefore the “cp” or existing “rsync -W” are not disadvantaged since the difference IS the whole file for some services. The use of unrealistically low log levels forces us to lift the bonnet on L2R to accommodate a log level that is unlikely to be seen for some time to come.
Oh and another minor point, I’ve noticed that the L2R logfile records very little (if anything) in cp mode whereas it logs the full --verbose output of rsync, so using rsync mode currently also adds to the logs being sync’d each time. If we start using L2R I would look at adding loglevels and more debugging logs to L2R eg the disk stats immediately before and after a L2R sync. And whilst I’m at it I would add a simple line to send the stats to a emonhub socket, so for debugging and running tests (or just displaying in emoncms) a “L2R” socket interfacer would just need enabling in emonhub, This would also help monitor multiple emonbases/Pi’s in a single emoncms. eg comparing several different logging strategies running on several test devices in one graph.