Following from discussion Device Module selecting wrong input and original emonhub development discussion here: EmonHub Development - #44 by TrystanLea I’ve put together a first attempt at implementing indexed inputs in emoncms, for early review and testing on sandbox systems (I wouldnt advise on running this on a live system yet) First attempt at indexed inputs by TrystanLea · Pull Request #1003 · emoncms/emoncms · GitHub
Indexed inputs
Starting with CSV
Emoncms has historically supported posting of CSV data in the following format:
input/post?node=mynode&csv=100,200,300
input/bulk?data=[[0,"mynode",100,200,300]]
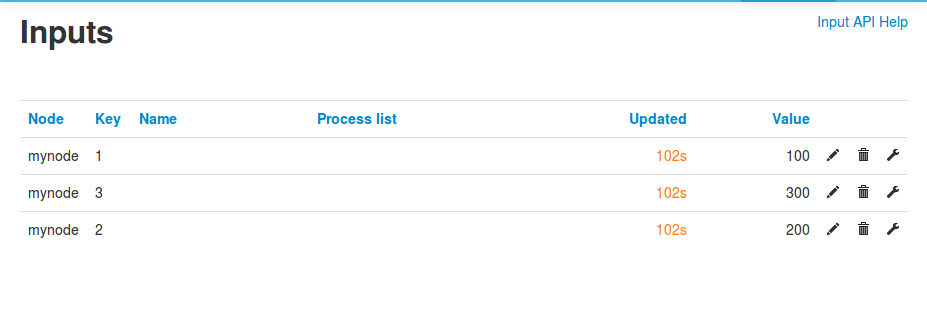
Emoncms automatically names each input in ascending order as received, our example above results in:
--node:mynode
-----name:1,value:100
-----name:2,value:200
-----name:3,value:300
If the name is then changed in the inputs interface, further posted inputs in csv format will recreate the original input name (e.g 1,2,3).
We can also post data using key:value json format:
input/post?node=mynode&json={"power1":100,"power2":200,"power3":300}
which results in:
--node:mynode
-----name:"power1",value:100
-----name:"power2",value:200
-----name:"power3",value:300
The proposal of indexed inputs is to separate the naming of inputs from the posting/updating of values when using CSV format. So that if we change the input names in the inputs interface and post to the csv API again, the values will apply to the new names according to the index order. This makes it possible to combine the benefits of named inputs that are a feature of the json key:value API with the compact size of CSV.
Using the adapted implementation in the indexedinputs branch, try changing the input key for CSV posted data from 1,2,3 to power1,power2,power3 in the inputs interface, using the pencil edit icon.
Post again with:
input/post?node=mynode&csv=100,200,300
Notice how new inputs are not created and that the renamed inputs are updated.
Its also possible to name the inputs directly in the API (note that posting names without values is not currently implemented):
input/post?node=mynode&csv=100,200,300&names=P1,P2,P3
and there’s the option to call csv: values which matches the emonhub naming convention:
input/post?node=mynode&values=100,200,300&names=P1,P2,P3
We can also update the same inputs using the JSON format, try:
input/post?node=mynode&json={"P1":100}
Starting with JSON
What happens if we start with JSON.
Step 1: Create a set of inputs with JSON format:
input/post?node=emontx&json={"power1":100,"power2":200,"power3":300}
These are indexed in received order, e.g power1 is index:0, power3 is index:2. If you now post another key:value seperately this will be indexed to index:3
input/post?node=emontx&json={"A":123}
Step 2: Post to the same inputs with CSV:
input/post?node=emontx&csv=100,200,300,123
A separate nodeid and nodename is not currently supported in this implementation which still makes it incompatible with the default emonhub http interfacer which posts the nodeid rather than nodename.
input->get_inputs function has been modified and use of this function in other parts of emoncms needs checking