True, but I don’t really “publish” as such. I hang onto the latest readings from each sensor and hand them over upon request from the host. I also provide a way for the host to do a bulk reading, so figured I should provide some indication of just how stale the data is on any one sensor. And if they’re really keen, I provide them a mechanism to request “do this one next”. If they do that just after I’ve started one going it could be a full 2 x 700 msecs before I have a fresh result for them though… and on average about 1 second later.
My environment is a bit too extreme to permit broadcast conversions. The power requirements and IR drop just make it too unreliable.
I’m not sure you can. The are-you-done-yet poll is not directed at any particular sensor. I’ve not tried it in a broadcast situation, but I imagine the rules are the same: respond with a 0 if still converting, respond with a 1 when complete. So at best you’d be able to tell if all the sensors have completed the conversion, but not which ones. That might be sufficient for your needs though?
I’ve just completed an overnight test of this topology:
All wiring cat5 except for the vertical line on the left, which re-purposes the obsoleted untwisted telephone cable run in from the street and through the walls.
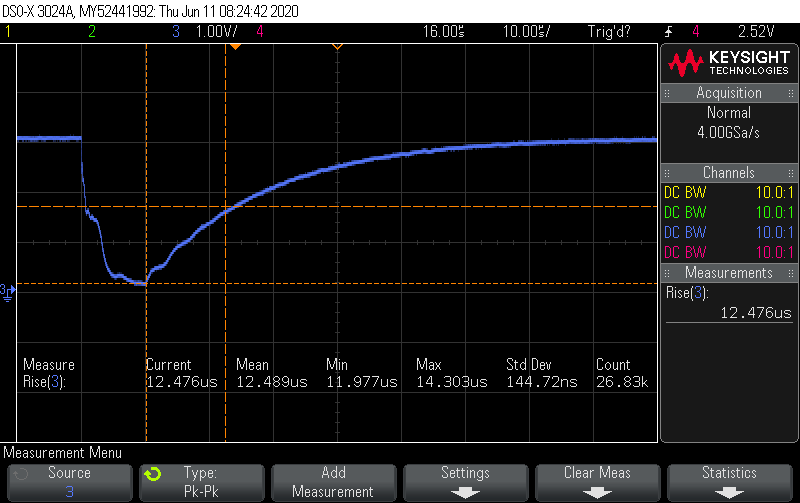
With that much load on the bus you need to dynamically adapt the bit timings based on the bus capacitance. Here’s how a return-to-1 looks on the scope (I’ve set the scope’s rise-time threshold to match the processors 0->1 threshold voltage):
You can see it bounces around a little but not enough to disturb things (12 usecs to 14.3 usecs). The code measures it constantly and adjusts the bit timings to match, so you can dump an extra 200m of cat5 on a live bus and it just keeps trucking.
The code measures the bus load at 12.49 usecs and in the overnight run did 75K conversions with just 1 soft error. If you drill down on that, it was a crc error while reading the scratchpad of one of the clones at the end of the 250m run, but on a retry it read fine. Since the conversion is the big time consumer, you don’t want to throw away the result because of a bit error in the reading. If I get 3 consecutive bit errors, I abandon that conversion, count it as a hard error, and try again next time around.
On a topology like that, everything just falls apart with broadcast conversion requests.