Hi Adrian
It sounds like we have been using the device module in similar ways. Prior to now, I thought of it as a very powerful tool but not overly user friendly, the sort of thing I would recommend a dev/admin using for rapid replication of complex processing, but not really ready for the casual user, mainly because the learning curve to only use it once or twice was a bit steep.
I have a load of templates and quite often they get edited for specific jobs as it’s easier to edit the template before each run than manually add all the inputs, processing and feeds the original way or even to edit after device creation.
I also have a bash script with some default.json files that I can just edit a couple of variables and it uses sed routines to change various keywords I have placed throughout my base templates, it then spits out a new single use json file for use in the device module. It sounds odd I know to produce single use templates but it really cuts my workload down no end, alas I know much of what I use is bespoke so I do not expect the device module to accommodate all my needs.
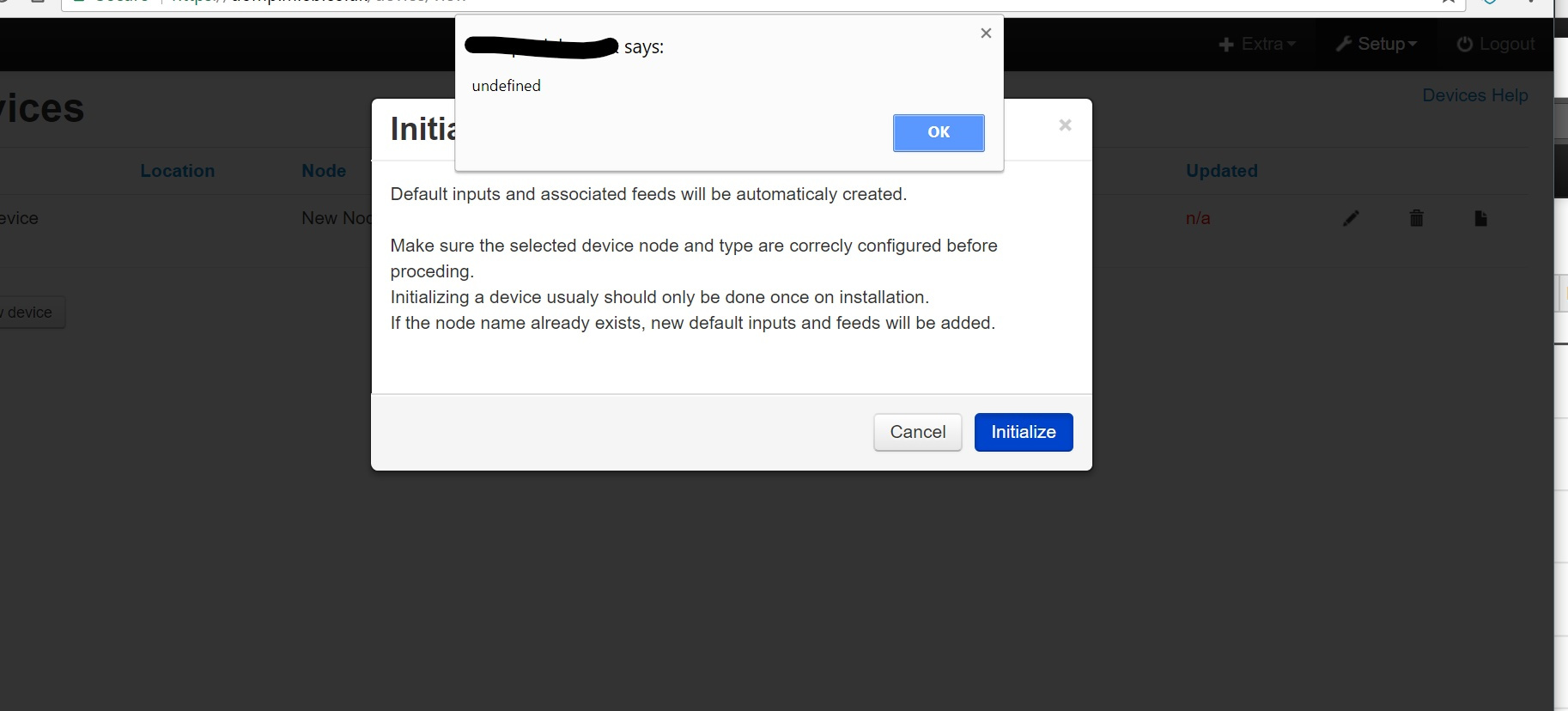
Personally, I would prefer the devices were not initialized as they were created. But it’s a minor point and may need rethinking anyway if there is to be a dry-run type confirmation.
Regards the API, there are many options, First is that users/scripts using the API directly will probably have greater confidence than the casual GUI user so there could be a simple assumed “force yes” arg to skip the dry-run. Or a second API can be used so the emoncms webpage can call “dryrun” first and “init” if confirmed, I imagined these to be the same process, where the expected result is output to screen rather than actually completing as I assumed the device module should check it can do the full initialization before starting it and fail part way through, although I’m guessing the new method should reduce the chance of it failing, previously it could create half the feeds before finding a duplicate and aborting, often ( I speak from experience) this could be caused by something as simple as a typo, the feed “power1” was created then the device initialization failed when it couldn’t find feed “pwer1” when incorrectly defined in the input processing, IMO any attempt to create this device (via API or GUI) should complain/fail before creating any feeds so IMO it should not create the first feed until it has done a “dry-run” regardless of whether user confirmation is requested, so pausing at the end of the first pass for the user to confirm would be a small addition in this instance.
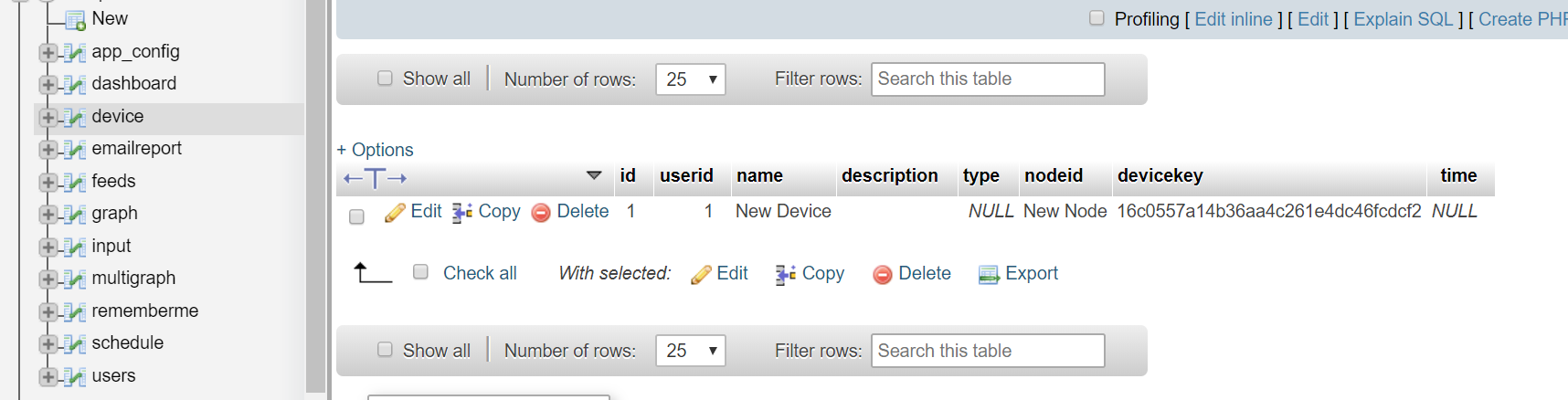
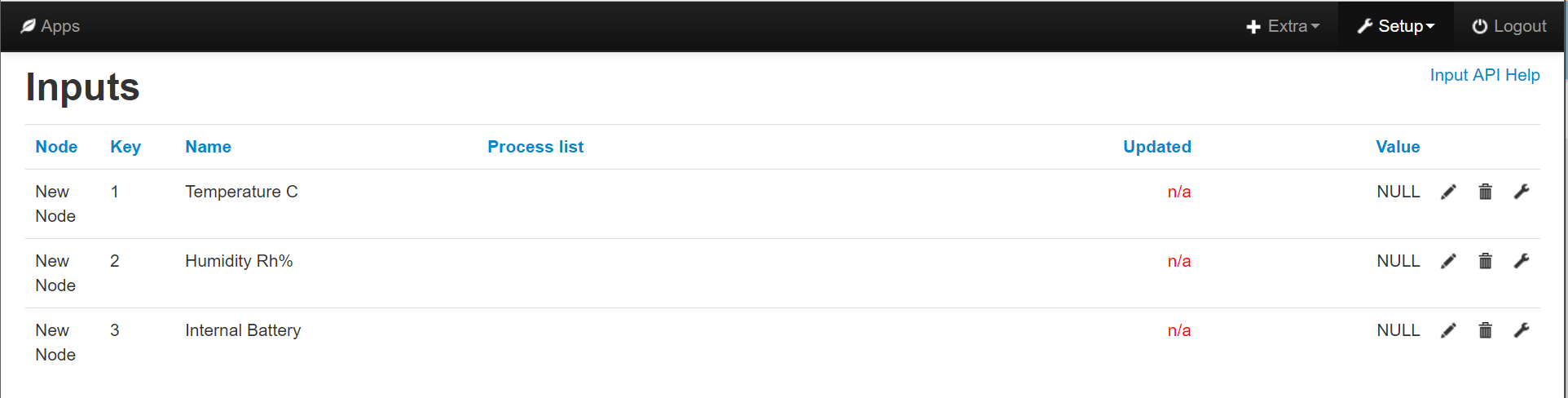
The thing that causes me the biggest headache is cross device totaling, I’m guessing that with this new version, because of the “just add what doesn’t already exist” approach. I’m hoping that I can add to that a facility to define feeds by tag and feedname in the input processing so I can create “summary” nodes, in which I can define 3x “Power1” feeds (tagged as L1, L2 & L3) and define a process list of +feed “L1: Power1”, +feed “L2: Power1”. +feed “L3: Power1”, logtofeed “Summary:PowerTotal” (not sure that would be acceptable syntax, but you get the gist), Then (hopefully) when the L1, L2 and L3 nodes are created they should use those 3 existing Power1 feeds. Currently I expect the tag for any feeds named in a processlist to be assumed to be equal to the nodename of that device, so defining +feed Power1 three times isn’t going to have the desired effect, but that is pretty much what I do now, I add 3x +feed “dummy_feed” and then go in afterwards and edit the target feed by selecting from the dropdown on the inputprocessing editing page.
I’m happy to help with any of this if I can as I do use it quite a lot, my php isn’t great but I can muddle though.
PS this isn’t a list of demands, just throwing idea’s out there for consideration, if my php was better and my diary slimmer, I would happily give it a go on my own.
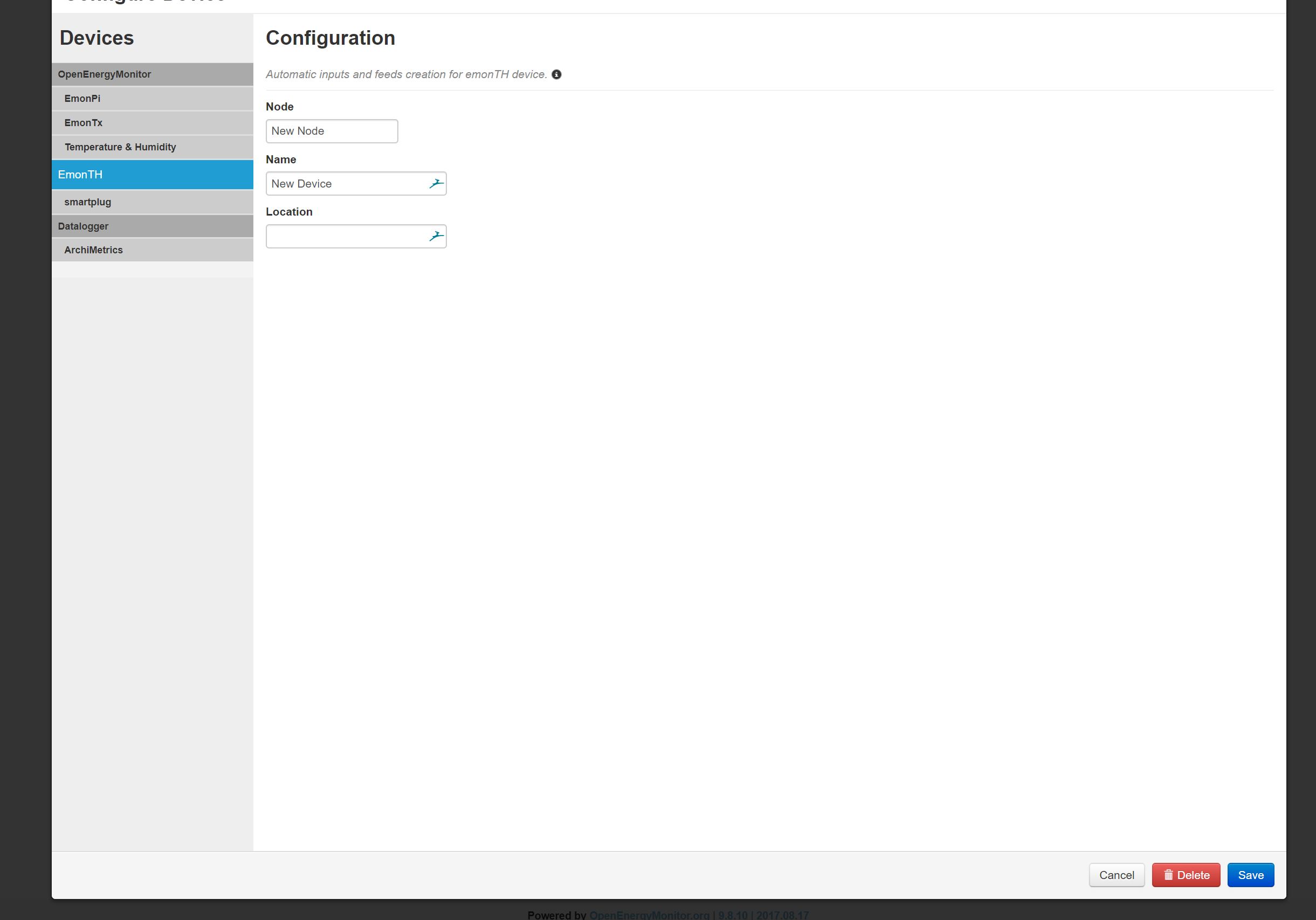

 and most of the necessary code can be copied but currently there is only one single api route ./device/template/init.json?id=1 with the device id as sole parameter to initialize the device… as the device type etc. can be fetched backend-wise.
and most of the necessary code can be copied but currently there is only one single api route ./device/template/init.json?id=1 with the device id as sole parameter to initialize the device… as the device type etc. can be fetched backend-wise.